Data Science
Naive Bayes Classification
Some basic statistical background.
A naive Bayes classifier is a machine learning algorithm that uses probability to classify data.
This algorithm assumes that all features are independent of
each other, given the target class.
This assumption is called class conditional independence.
It uses Bayes' theorem to calculate the probability of a class
given the data.
It assigns observations to the class with the highest
probability.
This is known as the maximum a posteriori (MAP) decision
rule.
Here is the classic Golf example.
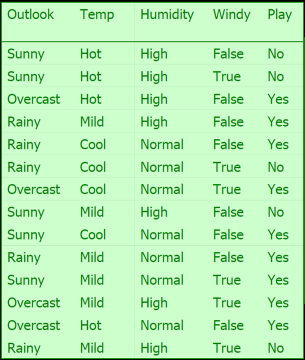
If today we have "sunny, cool, high, true", do you think it is a play or not?
How about "overcast, cool, high, true"?
Advantage of Naive Bayes Classifier
Easy to implement:
Due to its straightforward mathematical formulation, Naive Bayes
is considered one of the simplest classifiers to understand and
implement, making it a good starting point for beginners in
machine learning.
Fast prediction:
Calculations in Naive Bayes involve simple probability
calculations, leading to quick prediction times, making it
suitable for real-time applications.
Handles high-dimensional data:
Naive Bayes scales well with a large number of features, making
it effective for text classification problems where the feature
space can be very large.
Works well with small datasets:
Compared to other classifiers, Naive Bayes can perform well even
with relatively small amounts of training data.
Can handle both continuous and
categorical data:
Naive Bayes can be adapted to handle both numerical and
categorical features with appropriate probability distributions.