Data Science
Cross Validation
It’s easy to train a model against a particular dataset, but how does this model perform when introduced with new data? How do you know which machine learning model to use?
Cross-validation answers these questions by assuring a model is producing accurate results and comparing those results against other models.
Holdout Method
The holdout cross-validation method involves removing a certain portion of the training data and using it as test data. The model is first trained against the training set, then asked to predict output from the testing set. This is the simplest form of cross-validation techniques, and is useful if you have a large amount of data or need to implement validation quickly and easily.
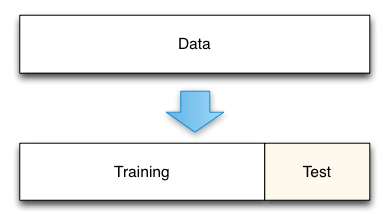
Typically the holdout method involves splitting a dataset into 20-30% test data and the rest as training data. These numbers can vary - a larger percentage of test data will make your model more prone to errors as it has less training experience, while a smaller percentage of test data may give your model an unwanted bias towards the training data. This lack of training or bias can lead to Underfitting/Overfitting of our model.
Leave-One-Out/Leave-P-Out Cross Validation
Leave-P-Out Cross Validation (LPOCV) tests a model by using every possible combination of P test data points on a model.
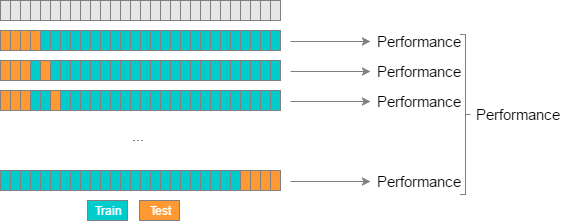
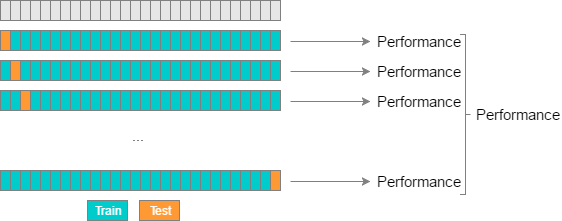
Leave-One-Out Cross Validation (LOOCV) is a commonly used cross-validation method. It is just a subset of LPOCV, with P being 1.
K-Fold Cross Validation
K-Fold Cross Validation helps remove these biases from your
model by repeating the holdout method on k subsets of your
dataset. With K-Fold Cross Validation, a dataset is broken up
into several unique folds of test and training data. The holdout
method is performed using each combination of data, and the
results are averaged to find a total error estimation.
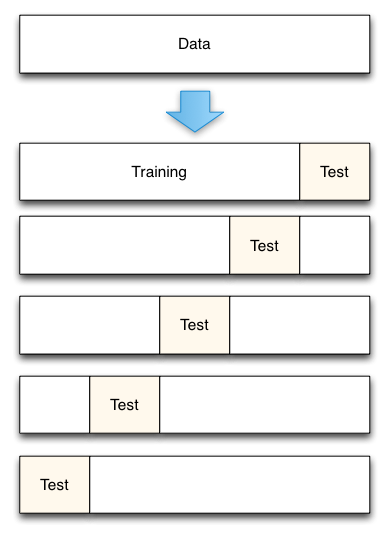
A “fold” here is a unique section of test data. For instance, if
you have 100 data points and use 10 folds, each fold contains 10
test points. K-Fold Cross Validation is important because it
allows you to use your complete dataset for both training and
testing. It’s especially useful when evaluating a model using
small or limited datasets.